

Full-text search for DynamoDB using Lambda, EFS, Tantivy and Rust.



TL;DR; The code for this blog post is available on Github.
Background
In serverless-land DynamoDB reigns supreme for data persistence. It is ridiculously fast, easy to use and scales to pretty much anything you throw at it. But the trick to using it successfully is that you have to carefully plan your access patterns up front. In situations where you want to do more complicated queries single-table design and filters can sometimes help, but for full-text search your out of luck, it doesn't support it.
For complicated search queries AWS recommends streaming data from DynamoDB to another database such as Elasticsearch. But setting up a whole Elasticsearch cluster can be complicated, plus it's expensive running servers 24-7. Another solution is to use Kinesis Firehose to send data to S3 which you can query with Athena. The downside of Athena is that it tends to be pretty slow especially for user-facing search requests. Depending on your use case there's obviously other solutions available outside of AWS such as Rockset, Algolia, Quickwit, ChaosSearch and Materialize.
While these are all great solutions, what's the fun in using some off the shelf product when we can build something ourselves right? In this article I want to show you a proof of concept that uses DynamoDB, Lambda and Rust to provide a blazingly fast serverless search experience. Depending on interest I could try and turn it into a more generic solution, e.g. a CDK construct that you point at a table and it takes care of the rest.
Proof of concept
For this proof of concept I'm going to model a service used to send emails. Emails will be sent using a service like Mailgun and stored in DynamoDB. We need need to be able to handle sending 100K emails per hour at peak. Messages can have multiple recipients. The service will also receive bounce notifications via webhooks. Lastly we only need to store messages for 90 days. We will rely on DynamoDB TTL to automatically delete items as they expire. Therefore our index will need to be able to support inserts, updates and deletes. For search we need to be able to:
- Filter by email address(es).
- Filter by keywords, or exact match phrases in the subject or body.
- Filter by date range (last hour, last 24 hours, last 7 days).
Solution discussion
Given we're using DynamoDB as our primary datastore we can take advantage of DynamoDB streams to bulk index the data as it changes. DynamoDB will buffer data until it reaches a configurable batch size / batch window before invoking lambda to do the indexing. To index the data we will be using Tantivy. Tantivy is a full-text search engine library inspired by Apache Lucene and written in Rust. It's an open source and maintained by the engineers at Quickwit.
We need somewhere to store the index so the main candidates would be S3 or EFS. EFS is a serverless elastic file system that you can attach to Lambda. It scales automatically and you only pay for the storage you use. EFS is also really fast, with sub-millisecond read latencies. Tantivy works out of the box with a filesystem so that's what I decided to run with.
One downside of EFS is that it runs within a VPC. We definitely don't want to create any NAT gateway instances as they are expensive to run. Without public internet access from our lambda functions we will need to use a VPC endpoint to access DynamoDB.
It's important to note that we don't need to store the entire document in the index -- just the terms and the ids of the emails. This helps reduce storage costs and allows Tantivy to do what it does best: indexing. Tantivy will return the ids from a query, then we will fetch the actual document from DynamoDB using a BatchGetItem request.
With Tantivy you can only have one process writing to the index at a time -- It locks the index while writing. So to ensure we only have a single index writer we will use provisioned concurrency set to 1 on the lambda and parallelization factor set to 1 on the stream. There's another potential problem here: scalability. If too much data arrives from the stream we might not be able to keep up. To help mitigate this problem it's important to use a large batch size / and batch window. If the indexing lambda cannot keep up you can get throttling, so for testing I've setup a SQS DLQ which we can check for failures. As always use load testing to ensure the solution will meet your requirements.
Architecture
Indexing flow
The email service will perform CRUD operations on DynamoDB. Changes are streamed in batches to the the "index writer" lambda function. It uses Tantivy to index the email and store it on EFS. It also acts as a "singleton" function, with only one instance of it running at a time.

Search flow
We are going to use a Lambda Function URL so that we can invoke the "index reader" lambda over HTTP using IAM authentication. The first thing the function will do is search the Tantivy index stored on EFS. Then using the ids returned, it will batch get the original documents from DynamoDB. This function can scale out because Tantivy supports having concurrent index readers.

Index Schema
Tantivy indexes have very strict schemas. The schema declares which fields are in the index and for each field its type and "how it should be indexed".
let mut builder = Schema::builder();
let id = builder.add_text_field("id", STRING | STORED);
let timestamp = builder.add_i64_field("timestamp", INDEXED);
let subject = builder.add_text_field("subject", TEXT);
let body = builder.add_text_field("body", TEXT);
let to = builder.add_text_field("to", TEXT);
let schema = builder.build();
For the id field we use STRING | STORED. STRING fields will be indexed and not tokenized. We also need to STORE the id in the index. This is important so that we can "update" a document. Tantivy does not support updates directly. Instead you have to perform a delete then insert before committing. There's an example of how perform an update operation in the examples.
For the timestamp field we use an i64 to store the Unix timestamp of the message. This field is INDEXED so that we can filter based on date e.g. last hour, last 24 hours, last 7 days.
For the rest of the fields we use TEXT. These fields will be tokenized and indexed.
When creating a document you can add the same field more than once. Below is a snippet from the "index writer" lambda function which parses events from DynamoDB and turns them into a Tantivy document. Notice we add a to field for each recipient.
fn parse_document(
config: &Config,
attributes: HashMap<String, AttributeValue>,
) -> anyhow::Result<Document> {
let id = parse_string(&attributes, "id")?;
let timestamp: i64 = parse_string(&attributes, "timestamp")?.parse()?;
let subject = parse_string(&attributes, "subject")?;
let body = parse_string(&attributes, "body")?;
let to = parse_string_array(&attributes, "to")?;
let mut doc = doc!(
config.email_index_schema.fields.id => id,
config.email_index_schema.fields.timestamp => timestamp,
config.email_index_schema.fields.subject => subject,
config.email_index_schema.fields.body => body,
);
for email in to {
doc.add_text(config.email_index_schema.fields.to, email);
}
Ok(doc)
}
Deployment
Setup a profile called "dynamodb-email-indexer". Don't skip this step! We use this within our package.json for deployments and testing.
aws configure --profile dynamodb-email-indexer
AWS Access Key ID [None]: ENTER YOUR ACCESS_KEY
AWS Secret Access Key [None]: ENTER YOUR SECRET_KEY
Default region name [None]: ENTER YOUR AWS_REGION
Default output format [None]:
Clone the code from Github
git clone https://github.com/jakejscott/dynamodb-email-indexer
cd dynamodb-email-indexer
Make sure the .env file is created
cp .env.sample .env
Fill out the fields with your AWS account id and region.
CDK_DEFAULT_ACCOUNT=ENTER YOUR AWS ACCOUNT_ID
CDK_DEFAULT_REGION=ENTER YOUR AWS_REGION
Install the latest version of the AWS CDK
npm install -g aws-cdk
Install the CDK dependencies
npm install
Make sure you have the latest version of Rust. I wrote a blog post if you need help.
rustup update
We need to cross compile our code to run on lambda. To do this we need to install an additional toolchain.
rustup target add x86_64-unknown-linux-musl
Build the Rust lambda functions. I created a utility program called package.rs to make this easy.
npm run package
Bootstrap CDK into the account your deploying into
npm run bootstrap
Finally, all going well, we should be able to deploy the stack!
npm run deploy
We have two stack outputs; the name of the DynamoDB table that is created, and a lambda function url for the index reader. Check that these have been written out to a file called outputs.json. Mine looks like this:
{
"dynamodb-email-indexer": {
"EmailIndexReaderFunctionUrl": "https://g4pvyrwfr65mpzjfb7f3wvlncy0vtpzf.lambda-url.ap-southeast-2.on.aws/",
"EmailTableName": "dynamodb-email-indexer-EmailTableEFC3BCB9-22OESOSH92FY"
}
}
Load testing writes
The first thing we should do is a smoke test to make sure everything is working. I created a benchmark.rs utility to make this easy.
cargo run --example benchmark -- --how-many 1000 --profile dynamodb-email-indexer
You should see some output similar to this
> dynamodb-email-indexer@0.1.0 benchmark
> cargo run --example benchmark -- --how-many 100 --profile dynamodb-email-indexer
[2022-04-14T00:36:42Z INFO benchmark] index num docs before starting: 34888
[2022-04-14T00:36:42Z INFO benchmark] sent 25 of 1000
[2022-04-14T00:36:42Z INFO benchmark] sent 50 of 1000
[2022-04-14T00:36:43Z INFO benchmark] sent 75 of 1000
[2022-04-14T00:36:43Z INFO benchmark] sent 100 of 1000
[2022-04-14T00:36:43Z INFO benchmark] sent 125 of 1000
...
[2022-04-14T00:36:44Z INFO benchmark] sent 925 of 1000
[2022-04-14T00:36:44Z INFO benchmark] sent 950 of 1000
[2022-04-14T00:36:45Z INFO benchmark] sent 975 of 1000
[2022-04-14T00:36:45Z INFO benchmark] sent 1000 of 1000
[2022-04-14T00:36:45Z INFO benchmark] checking total docs count
[2022-04-14T00:36:48Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 6.455459188s
[2022-04-14T00:36:51Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 9.665401669s
[2022-04-14T00:36:54Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 12.887532513s
[2022-04-14T00:36:57Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 16.106789721s
[2022-04-14T00:37:01Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 19.333715467s
[2022-04-14T00:37:04Z INFO benchmark] index num docs: 34888 total indexed: 0 elapsed: 22.573496403s
[2022-04-14T00:37:07Z INFO benchmark] index num docs: 35387 total indexed: 499 elapsed: 25.896673675s
[2022-04-14T00:37:11Z INFO benchmark] index num docs: 35632 total indexed: 744 elapsed: 29.187348488s
[2022-04-14T00:37:14Z INFO benchmark] index num docs: 35888 total indexed: 1000 elapsed: 32.713401804s
[2022-04-14T00:37:14Z INFO benchmark] done: 32.713490464s
Notice that the program queries how many documents are in the index before starting. It then starts sending documents to DynamoDB. Once it's finished sending the documents it keeps querying the index count until all documents have been indexed. In this case it took about 30 seconds to index 1000 documents.
Let's try indexing 10,000 records...
cargo run --example benchmark -- --how-many 10000 --profile dynamodb-email-indexer
Check the output, looks like it took 53 seconds to index 10,000.
[2022-04-14T00:46:08Z INFO benchmark] index num docs before starting: 35888
[2022-04-14T00:46:09Z INFO benchmark] sent 25 of 10000
...
[2022-04-14T00:46:30Z INFO benchmark] sent 10000 of 10000
[2022-04-14T00:46:30Z INFO benchmark] checking total docs count
[2022-04-14T00:46:34Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 26.661290598s
[2022-04-14T00:46:37Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 29.866499914s
[2022-04-14T00:46:40Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 33.511384528s
[2022-04-14T00:46:44Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 36.712733001s
[2022-04-14T00:46:47Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 39.926994794s
[2022-04-14T00:46:50Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 43.127705086s
[2022-04-14T00:46:53Z INFO benchmark] index num docs: 43888 total indexed: 8000 elapsed: 46.342801106s
[2022-04-14T00:46:57Z INFO benchmark] index num docs: 44466 total indexed: 8578 elapsed: 49.637049724s
[2022-04-14T00:47:01Z INFO benchmark] index num docs: 45888 total indexed: 10000 elapsed: 53.943496132s
[2022-04-14T00:47:01Z INFO benchmark] done: 53.94358911s
Lets try 100K records
cargo run --example benchmark -- --how-many 100000 --profile dynamodb-email-indexer
[2022-04-14T00:49:07Z INFO benchmark] index num docs before starting: 45888
[2022-04-14T00:49:10Z INFO benchmark] sent 25 of 100000
...
[2022-04-14T00:52:41Z INFO benchmark] sent 99975 of 100000
[2022-04-14T00:52:41Z INFO benchmark] sent 100000 of 100000
[2022-04-14T00:52:41Z INFO benchmark] checking total docs count
[2022-04-14T00:52:45Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 218.283679171s
[2022-04-14T00:52:48Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 221.598423283s
[2022-04-14T00:52:52Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 224.826200708s
[2022-04-14T00:52:55Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 228.106123255s
[2022-04-14T00:52:58Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 231.340136718s
[2022-04-14T00:53:02Z INFO benchmark] index num docs: 143888 total indexed: 98000 elapsed: 234.6622887s
[2022-04-14T00:53:05Z INFO benchmark] index num docs: 144820 total indexed: 98932 elapsed: 237.907739259s
[2022-04-14T00:53:08Z INFO benchmark] index num docs: 145467 total indexed: 99579 elapsed: 241.268484872s
[2022-04-14T00:53:12Z INFO benchmark] index num docs: 145888 total indexed: 100000 elapsed: 244.759438031s
[2022-04-14T00:53:12Z INFO benchmark] done: 244.759524446s
About 4 minutes to index 100K emails. Most of the time was spent sending the documents to DynamoDB too. You can see that by the time it started to check how many documents have been indexed, it was already at 98000.
How about 1 million?
[2022-04-16T00:33:58Z INFO benchmark] sent 999950 of 1000000
[2022-04-16T00:33:58Z INFO benchmark] sent 999975 of 1000000
[2022-04-16T00:33:58Z INFO benchmark] sent 1000000 of 1000000
[2022-04-16T00:33:58Z INFO benchmark] checking total docs count
[2022-04-16T00:34:03Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2060.0101917s
[2022-04-16T00:34:06Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2063.231698s
[2022-04-16T00:34:09Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2066.4664465s
[2022-04-16T00:34:12Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2069.6761106s
[2022-04-16T00:34:16Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2073.0062907s
[2022-04-16T00:34:19Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2076.2273748s
[2022-04-16T00:34:22Z INFO benchmark] index num docs: 999000 total indexed: 999000 elapsed: 2079.4475651s
[2022-04-16T00:34:26Z INFO benchmark] index num docs: 999634 total indexed: 999634 elapsed: 2082.9070893s
[2022-04-16T00:34:29Z INFO benchmark] index num docs: 1000000 total indexed: 1000000 elapsed: 2086.2907929s
[2022-04-16T00:34:29Z INFO benchmark] done: 2086.2912984s
About 34 minutes to index 1M documents, again with most of the time spent sending the docs to DynamoDB and the index only trailing by about 30 seconds! I think we can say that it meets our goal of being able to index 100K emails per hour ✅.
Loading testing reads
We also need to load test how many queries we can do per second. To make this easier I disabled the IAM Auth on the lambda function URL. I'm using k6 to run the load test. This is the test script:
import http from "k6/http";
import { check, sleep } from "k6";
export const options = {
stages: [
{ duration: "15s", target: 10 },
{ duration: "30s", target: 25 },
{ duration: "60s", target: 50 },
{ duration: "20s", target: 0 },
],
thresholds: {
// 95% of requests must finish within 100ms.
http_req_duration: ["p(95) < 100"],
},
ext: {
loadimpact: {
distribution: {
"amazon:au:sydney": { loadZone: "amazon:au:sydney", percent: 100 },
},
},
},
};
export default function () {
const url = __ENV.URL;
const query = __ENV.QUERY;
const limit = parseInt(__ENV.LIMIT);
const payload = JSON.stringify({
query: query,
limit: limit,
});
const params = {
headers: {
"Content-Type": "application/json",
},
};
const res = http.post(url, payload, params);
check(res, { "status was 200": (r) => r.status == 200 });
const json = res.json();
check(json, {
"no errors": (x) => x.error == null,
});
sleep(1);
}
From my machine we are able to get about 21 requests per second, with 95% of all requests finishing in under 100ms. The stack is deployed in Sydney (ap-southeast-2), while I live in New Zealand so there's a bit of latency.
k6 run -e QUERY="to:jaeden.shields@hotmail.com" -e LIMIT=10 -e URL=https://mnitgr7azia56rmhypjltqitlu0ggqmd.lambda-url.ap-southeast-2.on.aws .\loadtest\index.js
/\ |‾‾| /‾‾/ /‾‾/
/\ / \ | |/ / / /
/ \/ \ | ( / ‾‾\
/ \ | |\ \ | (‾) |
/ __________ \ |__| \__\ \_____/ .io
execution: local
script: .\loadtest\index.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 2m5s max duration (incl. graceful stop):
* default: Up to 50 looping VUs for 1m35s over 4 stages (gracefulRampDown: 30s, gracefulStop: 30s)
running (1m35.3s), 00/50 VUs, 2085 complete and 0 interrupted iterations
default ✓ [======================================] 00/50 VUs 1m35s
✓ status was 200
✓ no errors
checks.........................: 100.00% ✓ 4170 ✗ 0
data_received..................: 1.6 MB 17 kB/s
data_sent......................: 576 kB 6.0 kB/s
http_req_blocked...............: avg=3.34ms min=0s med=0s max=237.28ms p(90)=0s p(95)=0s
http_req_connecting............: avg=1.05ms min=0s med=0s max=102.87ms p(90)=0s p(95)=0s
✓ http_req_duration..............: avg=60.71ms min=43.92ms med=57.27ms max=368.81ms p(90)=70.92ms p(95)=79.93ms
{ expected_response:true }...: avg=60.71ms min=43.92ms med=57.27ms max=368.81ms p(90)=70.92ms p(95)=79.93ms
http_req_failed................: 0.00% ✓ 0 ✗ 2085
http_req_receiving.............: avg=180.73µs min=0s med=0s max=4.76ms p(90)=808.3µs p(95)=1ms
http_req_sending...............: avg=5.64µs min=0s med=0s max=925.8µs p(90)=0s p(95)=0s
http_req_tls_handshaking.......: avg=2.24ms min=0s med=0s max=193.67ms p(90)=0s p(95)=0s
http_req_waiting...............: avg=60.53ms min=42.96ms med=57.09ms max=368.81ms p(90)=70.66ms p(95)=79.93ms
http_reqs......................: 2085 21.870785/s
iteration_duration.............: avg=1.07s min=1.04s med=1.06s max=1.37s p(90)=1.08s p(95)=1.1s
iterations.....................: 2085 21.870785/s
vus............................: 2 min=1 max=50
vus_max........................: 50 min=50 max=50
Let's run the test using k6.io cloud. First login to k6
k6 login cloud -t YOUR_K6_CLOUD_TOKEN
Next run the script in the cloud using k6 cloud rather than k6 run.
k6 cloud -e QUERY="to:jaeden.shields@hotmail.com" -e LIMIT=10 -e URL=https://mnitgr7azia56rmhypjltqitlu0ggqmd.lambda-url.ap-southeast-2.on.aws .\loadtest\index.js
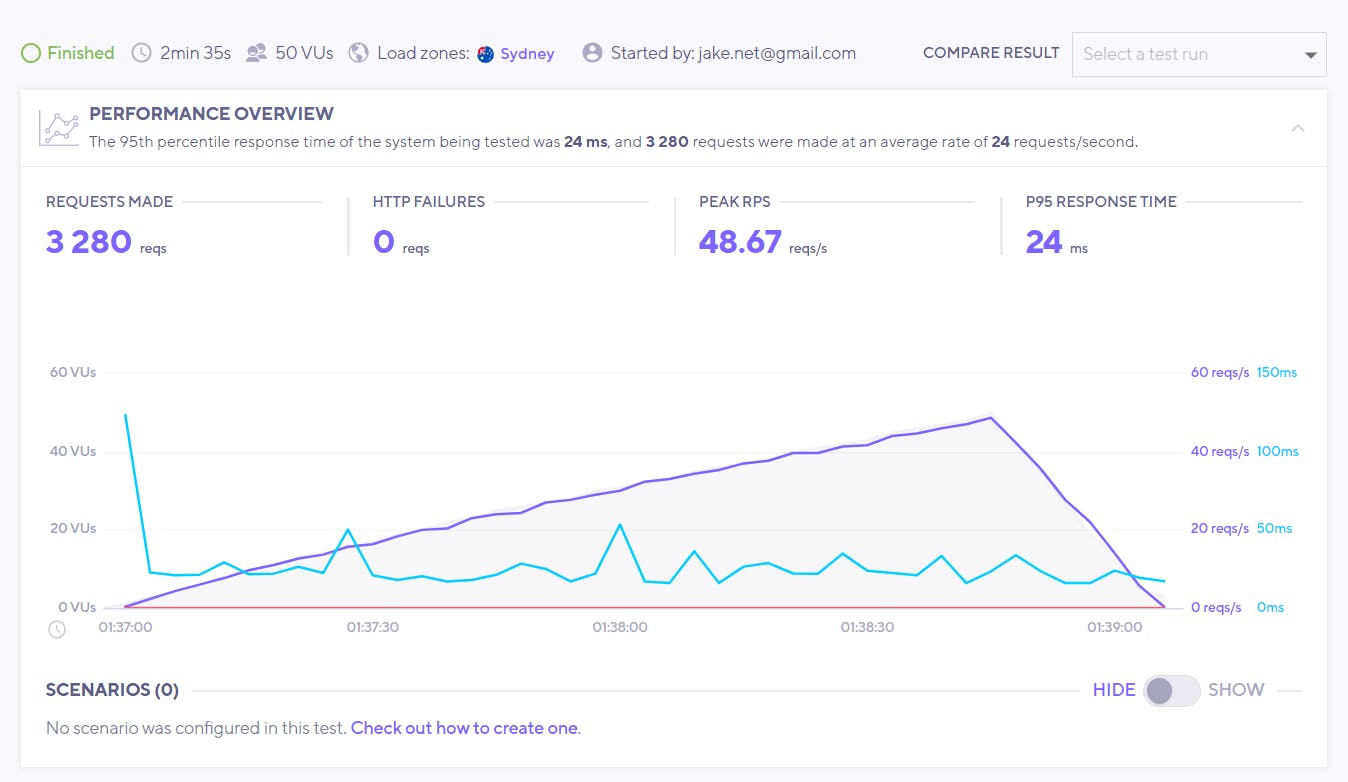
With the k6 trial account I'm only able to create 50 virtual users and it looks like we peak at about 50 req/s. The average response time stays flat during the test which is good, but we'd probably need to add more users to see how well it scales. I think we can give this a pass for now 😊.
Search testing
Filter by email address:
cargo run --example search -- --query 'to:reina.medhurst@yahoo.com' --limit 10 --profile dynamodb-email-indexer
Response:
[2022-04-14T02:05:12Z INFO search] search response:
{
"emails": [
{
"body": "ratione beatae ratione officia et.\nquos eveniet alias fuga unde doloremque aperiam.",
"id": "01G06C7J8T0AKNJVZT8H5X083S",
"subject": "inventore maxime quia ea.",
"timestamp": 1649481599,
"to": [
"\"Reina Medhurst\" <reina.medhurst@yahoo.com>"
]
}
],
"error": null,
"index_num_docs": 145888,
"query_num_docs": 1
}
[2022-04-14T02:05:12Z INFO search] done: 260.592ms
Filter by email addresses:
cargo run --example search -- --query 'to:reina.medhurst@yahoo.com OR to:lolita.kulas@hotmail.com' --limit 10 --profile dynamodb-email-indexer
Response:
[2022-04-14T02:04:24Z INFO search] search response:
{
"emails": [
{
"body": "dignissimos consectetur doloremque enim nam ut quo.",
"id": "01G06C7J8Z46A9FVWQABWMD8K6",
"subject": "illum ut.",
"timestamp": 1649481599,
"to": [
"\"Lolita Kulas\" <lolita.kulas@hotmail.com>"
]
},
{
"body": "ratione beatae ratione officia et.\nquos eveniet alias fuga unde doloremque aperiam.",
"id": "01G06C7J8T0AKNJVZT8H5X083S",
"subject": "inventore maxime quia ea.",
"timestamp": 1649481599,
"to": [
"\"Reina Medhurst\" <reina.medhurst@yahoo.com>"
]
}
],
"error": null,
"index_num_docs": 145888,
"query_num_docs": 2
}
[2022-04-14T02:04:24Z INFO search] done: 227.0634ms
Filter by keywords, or exact match phrases in the subject or body.
cargo run --example search -- --query 'subject:magni+asperiores AND body:quasi+debitis+rerum+tempore+doloribus' --limit 10 --profile dynamodb-email-indexer
Response:
[2022-04-14T02:02:34Z INFO search] search response:
{
"emails": [
{
"body": "quasi debitis rerum tempore doloribus.",
"id": "01G0JRQ6ZY1CGNM60YSX41A314",
"subject": "magni asperiores.",
"timestamp": 1649897348,
"to": [
"\"Nya Jenkins\" <nya.jenkins@yahoo.com>"
]
}
],
"error": null,
"index_num_docs": 145888,
"query_num_docs": 1
}
[2022-04-14T02:02:34Z INFO search] done: 267.226ms
Filter by date range
cargo run --example search -- --query 'timestamp:>=1649481599 AND timestamp:<=1649902135' --limit 5 --profile dynamodb-email-indexer
Response
[2022-04-14T02:10:33Z INFO search] search response:
{
"emails": [
{
"body": "esse quas amet voluptatibus.",
"id": "01G06C7J92JMCT94A5SA9JH31N",
"subject": "deserunt.",
"timestamp": 1649481599,
"to": [
"\"Torrey Wyman\" <torrey.wyman@gmail.com>"
]
},
{
"body": "ratione beatae ratione officia et.\nquos eveniet alias fuga unde doloremque aperiam.",
"id": "01G06C7J8T0AKNJVZT8H5X083S",
"subject": "inventore maxime quia ea.",
"timestamp": 1649481599,
"to": [
"\"Reina Medhurst\" <reina.medhurst@yahoo.com>"
]
},
{
"body": "aut rem sit commodi ipsam labore nam ut minima.\nnatus est vero sit assumenda maxime.",
"id": "01G06C7J98DQP0R7EG7BZQQRH9",
"subject": "veritatis reprehenderit suscipit.",
"timestamp": 1649481599,
"to": [
"\"Colten Jerde\" <colten.jerde@yahoo.com>"
]
},
{
"body": "ut alias aperiam porro excepturi eum beatae.",
"id": "01G06C7J91F35Z77ANADB6D2R0",
"subject": "est.",
"timestamp": 1649481599,
"to": [
"\"Alisha Gutmann\" <alisha.gutmann@yahoo.com>"
]
},
{
"body": "dignissimos consectetur doloremque enim nam ut quo.",
"id": "01G06C7J8Z46A9FVWQABWMD8K6",
"subject": "illum ut.",
"timestamp": 1649481599,
"to": [
"\"Lolita Kulas\" <lolita.kulas@hotmail.com>"
]
}
],
"error": null,
"index_num_docs": 145888,
"query_num_docs": 145885
}
[2022-04-14T02:10:33Z INFO search] done: 207.5986ms
Next steps
I'd love to spend some time thinking about how to turn this into a more generic solution or open source project that could be packaged up in the form of a CDK construct. These are some of the features I've thought about:
- Indexing an existing table (could start from a DynamoDB table backup).
- Ability to manage indexes, modify, re-index etc.
- Rolling index per day / month
- Admin UI using Remix and Tailwind UI.
- Other use cases like being able to search EventBridge events.
If this is something that you're interested in please reach out to me on Twitter or leave a comment or star the Github repo. If you want to learn more about Tantivy check out the examples and join the Quickwit discord channel, they are very helpful and have answered a bunch of my questions.
Thanks for reading!